
Možná jste dosud nevěděli, že společnost Facebook provozuje laboratoř na výzkum umělé inteligence. Vyhlídka na porozumění textu má totiž pro Facebook velký význam. Firma stále hledá způsoby, jak lépe vybírat, které příspěvky vám zobrazí na úvodní stránce, aby vás chození na Facebook neomrzelo. Neopomeňme ovšem i to, že Facebook žije z reklamy — cílené a pokud možno kontextové.
Soudě podle nedávno zveřejněného výzkumu, pod nímž jsou podepsáni čtyři pracovníci laboratoře v New Yorku, nebude to se strojovým porozuměním obsahu našich příspěvků na Facebooku zatím nikterak žhavé. Umělá inteligence se stále zdá být „v plenkách“ — působí zatím jako nepříliš bystré, ještě hodně malé dítě.
Na výzkumu se podílel Tomáš Mikolov; má doktorát z brněnského VUT a podíval se už do Microsoftu a do Googlu, než nastoupil k Facebooku.
Dvacet prubířských úloh
Výzkumníci sestavili sadu logických úloh zakončených otázkou nebo otázkami. Netvrdí, že schopnost vyřešit tyto úlohy postačuje k tomu, abychom řešící stroj uznali za inteligentní, nicméně prohlašují, že neschopnost vyřešit kteroukoli z úloh je zásadní překážkou k úspěšnému porozumění přirozenému jazyku.
Všechny úlohy jsou sestavené tak, aby vedly na odpovědi jednoznačné a až na výjimky jednoslovné (odmyslíme‑li si například to, že mluvnice některého jazyka by žádala navíc třeba předložku). Za přínos svého výzkumu autoři považují snadnou vyhodnotitelnost odpovědí: je možné vzít kterýkoli model aspirující na porozumění textu a jednoznačně jej podrobit této zkoušce.
To autoři také s několika modely učinili, včetně vlastního modelu „Memory Networks“, který tři ze čtveřice autorů vydali na podzim. „Memory Networks“ nyní vylepšili několika doplňky, přesto však model nedokázal vyřešit všechny úlohy.
Hádanky jako z mateřské školy
Nejjednodušší úloha zní:
Jan je na hřišti.
Bob je v kanceláři.
Kde je Jan?
Obtížnost úloh postupně vzrůstá:
Jan je na hřišti.
Bob je v kanceláři.
Jan vzal míč.
Bob šel do kuchyně.
Kde je míč?
Kde byl Bob, než šel do kuchyně?
Dvacátá úloha zní:
Jan je hladov.
Jan jde do kuchyně.
Jan sní jablko.
Daniel je hladov.
Kam půjde Daniel?
Proč šel Jan do kuchyně?
Všech dvacet úloh v angličtině naleznete v oddíle 3 vydané zprávy, očíslovány jsou 3.1 až 3.20 a prověřují různé logické dovednosti, jejichž seznam najdete také v tabulce níže. Podstatným rysem úloh je, že všechny jsou jednoznačně řešitelné člověkem.
Syntetický svět
Všechny úlohy se odehrávají v omezeném, umělém, vnitřně soudržném světě postaveném na způsob dávných textových „adventur“: ve světě je jen několik osob, několik navazujících míst a několik předmětů. Osoby a předměty se vždy nacházejí na určitém místě (některé předměty mohou skrývat jiné předměty) a mají omezený počet vlastností a stavů. Celý svět lze popsat slovníkem o 150 slovech.
Modely vyvíjené a zkoušené výzkumníky nejsou však vázány na angličtinu, cílem je vytvořit systém schopný učit se z pokud možno jakýchkoli dat. Stejné úspěšnosti dosáhnou modely na datových množinách s nahrazenými písmeny. Dva odstavce níže mají pro stroj týž „smysl“:
Mary got the milk there.
John moved to the bedroom.
Is John in the kitchen?
Utxi rbq qzh yeuk qzhxh.
Hbzm ybnha qb qzh phaxbby.
Xl Hbzm em qzh keqozhm?
Pro stroj bez další souvisící znalosti vypadá každá z těchto úloh jen jako shluky znaků. Ale opakováním lze vycvičit jej k tomu, že umí nalézt správnou odpověď. Několik úloh se však tomuto postupu dosud vymyká:
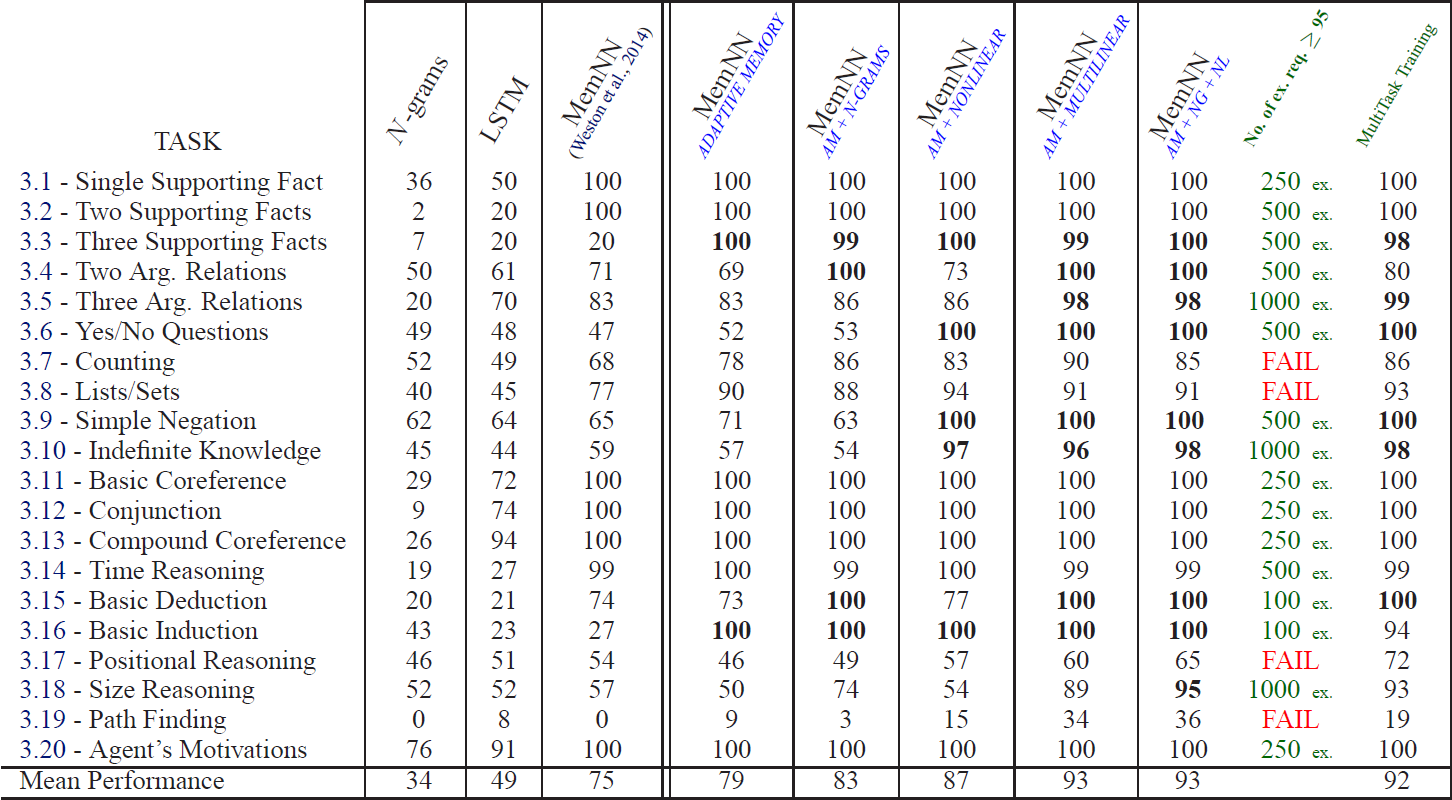
Čísla ve sloupcích vyjadřují procentuální správnost odpovědí poskytovanou jednotlivými modely, ale až po tisíci cvičebních příkladech. Předposlední sloupec vyjadřuje počet cvičebních příkladů nutný k získání 95% úspěšnosti, pokud jde o model „MemNN AM+NG+NL“.
S čím si modely dosud neporadí?
Autoři nedokázali získat ani od nejlepšího ze zkoušených modelů spolehlivé řešení čtyř úloh z dvaceti, a to těchto:
3.7 spočítání předmětů
Daniel vzal míč.
Daniel pustil míč.
Daniel vzal mléko.
Daniel vzal jablko.
Kolik předmětů drží Daniel?
3.8 výčet předmětů
Daniel vzal míč.
Daniel pustil noviny.
Daniel vzal mléko.
Co drží Daniel?
3.17 porovnání polohy
Trojúhelník je napravo od modrého čtverce.
Červený čtverec je na modrém čtverci.
Červená koule je napravo od modrého čtverce.
Je červená koule napravo od modrého čtverce?
Je červený čtverec nalevo od trojúhelníku?
3.19 nalezení cesty
Kuchyně je na sever od chodby.
Pokoj je na východ od chodby.
Kterými směry dojít z pokoje do kuchyně?
I pokud jde o vykázanou úspěšnost, ta závisí na tom, že modely jsou při učení „voděny za ručičku“ — v učebních datech je výslovně uvedeno, na kterém řádku hledat odpověď. Bez této nápovědy („supervize“) by výsledky modelů byly mnohem horší.
Skutečná umělá inteligence je stále vzdálená
„Současný stav výzkumu umělé inteligence je na mnohem nižší úrovni, než se obvykle prezentuje,“ sdělil Lupě svůj soukromý názor výzkumník Tomáš Mikolov. „Mnohé systémy, které jsou v současnosti prezentovány jako špička ve výzkumu AI, vlastně nemají s umělou inteligencí moc společného. Příkladem mohou být Siri od Applu nebo Watson od IBM — můžete jim uvádět nové příklady chování po libovolně dlouhou dobu, ale nikdy se od vás ničemu novému nenaučí — kromě několika předdefinovaných vzorců, jako například jaké je vaše jméno, ale pokud pro to nejsou výslovně naprogramovány, už se třeba nedokáží naučit, jakým jezdíte autem.

Zjednodušeně řečeno — Watson a spol. vypadají inteligentně, protože si pamatují spoustu faktů; jsou to však jen velké databáze, ničemu se neučí v průběhu ‚života‘. Stávající AI techniky umožňují sice omezené učení, ale spíše jen tak, že si zapamatují všechno doslova. Zjednodušeně lze říci, ze malou násobilku se můžete ‚naučit‘ i tak, že si prostě zapamatujete všechny kombinace vstupních čísel a výsledků, jenže takové učení vám nepomůže k násobení větších čísel — na to je třeba naučit se algoritmus.
Učení se podobným způsobem jako lidé je cílem výzkumu umělé inteligence, jen nikdo zatím neví, jak přesně na to. Ale snažíme se o systém, se kterým bude možné komunikovat v běžném jazyce a který bude schopen rychle se z komunikace učit novým poznatkům.“






























 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU